
浅谈分布式渗透框架的架构与设计

本文与大家探讨一些关于分布式渗透框架的架构与设计的话题,分享笔者的一些拙见,希望能对大家有所启发。本文分为三个话题(Topic),建议按顺序阅读,在三个话题中,笔者对两个痛点(架构设计与通信)做了一些细节描述。
- Topic - 渗透测试框架是什么
- Topic - 需求分析与架构设计
- Topic - 通信与消息队列
Topic - 渗透测试框架是什么
背景
现在很多大小厂家或者很多私人团队都在做或者已经有成熟的扫描器,开源也好内部使用也好。都是为了解决一些实际的问题:
- 渗透测试需要
- 代替重复手动来动
- 避免遗漏发生
- 传承/继承优秀的测试方法
- 作为企业的产品之一
- 面向专业用户
- 面向普通用户
- 灰色产业(BOTNET)
简单来说,渗透测试框架能让你的某些渗透测试流程变的更简单,辅助业务完成,简化一些业务逻辑。当然对于框架来说,它的基本功能其实是保证插件的正常运行。当他拥有了很多的插件的时候,价值才会真正体现出来。
本质
渗透测试框架并不是什么特别高深的东西,相比电商系统中的微服务架构,可能基础架构并没有它复杂,甚至相比之下可以说是小巫见大巫了。但是渗透测试框架也并不适合和微服务架构进行对比,因为它更加的灵活,一些高级开发概念(分布式/微服务),对他并不是特别适用。一个渗透测试框架/扫描器,可以非常简洁明了,甚至可以看成一个灵活的脚本引擎,但是同时又存在着很多的大型的渗透框架/扫描框架(Nessus/OpenVAS),这些框架的复杂程度远远高于普通的脚本引擎。说渗透测试框架/扫描器的本质,并不好根据他的特征说具体它是一个什么样的程序:
- 一个单机运行/分布式的程序框架
- 高质量的扫描模块,或者灵活的脚本引擎
- 稳定的基础设施,逻辑可编程控制
解决的问题
- 代替某些重复的手工劳动
- 固定逻辑输出
- 稳定的输出
不能解决的问题
- 带有复杂逻辑的漏洞无法检测
- 分布式渗透框架设计与实现难度高
普适性的规则
对于一个这种框架来说,再简化简化简化模型,它最终会变成一个 RPC(Remote Procedure Call)调用多种程序(功能单元)的框架,当然这里不是说具体的 RPC 协议,而是一个泛化的 RPC 的概念;或者变成一个直接调用多种程序(功能单元)的框架。
与普通 RPC 最大的差别就是:任务种类多样,任务可能存在更新的情况,执行任务环境非常复杂。而且框架本身需要支持高度灵活的功能单元(插件)。或者用另一句话来说,被调用的程序(功能模块)对于框架来说,是非常非常松散的,甚至失效/过时都不会影响任何框架的运行。
这样来说,它又不能简单的说是一个 RPC,基于上述的情形,他在设计的时候,排除后期模块注册等机制,框架本身是不能主动知道他会有多少种类,多少数量的程序可以让他在远程调用,同时也不知道这些程序的基础接口到底是什么。因此用 RPC 来描述,又不是特别恰当。
那么,在对于框架来说,我们最好采用哪种形式来描述?当然,每个人有每个人的看法,我更偏向于使用 松散的主从架构(Loose Master-Slave) 这样的描述来作为这类框架的架构模型:自然 Slave 表示功能单元或者被调用的程序,Master 则代表控制器/调用者或者整体事务逻辑处理的节点,Loose 则代表了 Slave 和 Master 之间的关系,相互的依赖性不是特别的强,可以采用其他的机制来维护他们之间的联系,比如注册或订阅机制等。
补充说明
当然框架和渗透测试工具是不一样的,工具大可直接使用分层架构,甚至可以不用太注意项目模型和结构相关的部分,直接面向过程实现某一些特定功能,或者部分或者整体使用微内核架构提供一定的灵活性。
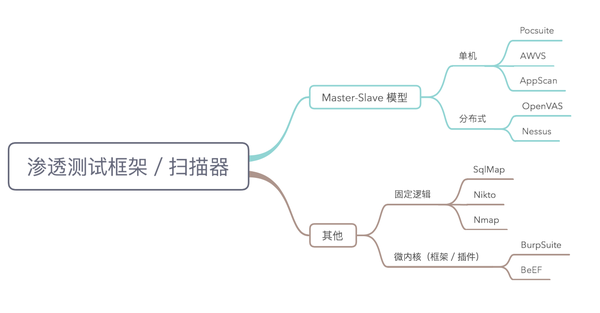
现主流扫描器/框架的模型分类
- 单机与分布式:本文中单机与分布式的最大的区别不是是否联网,而是具体的执行任务的工作节点是否在一台机器上。
- 微内核架构:这种架构非常灵活,既可以作为部分也可以作为整体框架使用。比如常见的脚本引擎:Nmap 的 NSE 系统,SQLMAP 的 Tamper 机制等等,其实可以说用到了微内核模型的一些思想。
- 微内核与主从:微内核采用主从模型,在一定程度上解耦功能模块。

在下一个话题中,我们讨论分布式渗透框架/扫描器的架构设计相关的话题。
Topic - 需求分析与架构设计
背景
简单来说这个框架的任务就是,接收任务,分发任务,执行任务,处理结果,因此分布式渗透测试框架相对于电商平台的微服务架构要简单很多,因为渗透测试框架的事务相对更佳简单一些,甚至可以说淡化事务这个概念。但是又属于任务密集型的应用,一定程度上高并发和高可用性又存在一定的需求。
我们可以从头梳理一下整个过程,Master 得到一个任务,这个任务被分为几个原子任务,按照种类被送给了不同的 Worker,然后任务执行之后,结果被发送会 Master,进行事务汇总。
整个过程虽然并不是非常的复杂,但是我们还是需要分析一下我们到底需要什么才能针对需求作出合理的架构设计
需求
思考了很多关于需求描述的方法,我们没有办法只从一个角度很好的描述我们的系统到底需要什么样的功能,这就好比我们有了 OOP,但是 AOP 的出现进行了对 OOP 非常好的补充,当然还有 SOP(面向状态编程)也对 OOP 的起到了很好的补充。啊,话题扯远了,经过一些思考,分别从空间和时间(过程/逻辑)两个角度来讨论我们的需求。
- 空间角度是指对象,行为,数据,实体角度与传统的 OOP 的思考角度类似,就不做过多的赘述了。
- 时间/过程/逻辑角度指的是我们从个行为从开始到结束整个过程来思考问题,就比如,从 Master 到 Slave 通信的整个过程,一个事务的生存周期(任务从产生到结束或者被丢弃),一个模块的生存周期,一个存在主逻辑的调度过程等。
空间需求
从功能实体的角度来说,我们大概需要这样的东西:
Master
- 事务管理
- 任务接收
- 任务分发
- 结果收集
- 节点管理
- 节点审计(Inspect)
- 节点启停(Start / Stop)
- 用户管理
- 略
Slave
- 状态无关
- 事务处理
- 任务执行
- 结果返回
- 节点管理
- 节点状态汇报
时间/过程/逻辑需求
当然这里指的是本框架中为了解决问题从而需要的一系列的机制或者可能出现的过程或者逻辑
- 通信系统(稍后会详细讨论)
- 事务系统
- 任务管理系统
- 结果管理系统
- 功能模块引擎
- 高度模块化:指的是模块之间高度独立,极低耦合甚至没有耦合
- 使用脚本引擎提升灵活性:针对不必要新建模块的小型任务,仅使用一个脚本引擎来敏捷启动和执行任务
- 对框架的低依赖:模块按照一定规范编写而成,不需要向框架提供任何接口
- 接口统一,但是模块本身环境的多样性:模块可以是任意的语言,任意的环境,任意容器,但是模块的接口必须是框架可以接受的
- 调度系统
存在一个可以让模块协同工作的调度系统。
- 用户接口(略)
- 框架扩展系统
- 任务脚本 SDK
- 关键点/关键消息队列拓展
设计
根据我们需求,最简单的,我们整体的架构应该是一个松散的 Master-Slave 架构,Master 并不依赖任何 Slave,但是 Slave 必须依附于 Master 才可以工作。
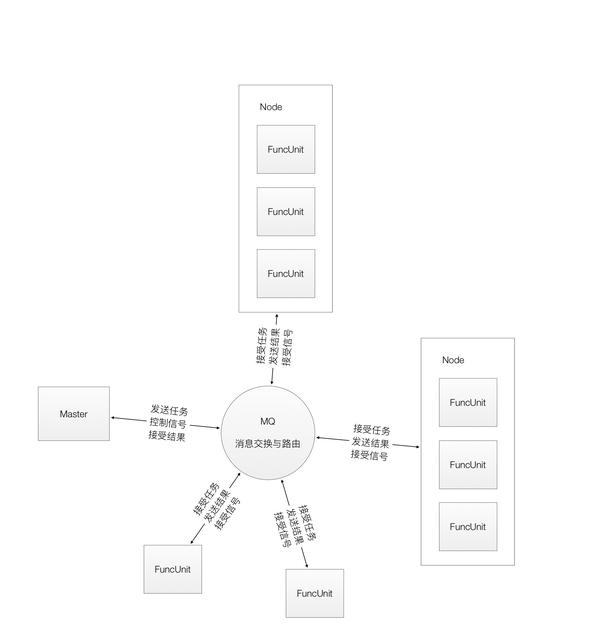
在进行下面的叙述过程中,我们首先约定一下在我们的框架中要出现的几个概念:
- Master - 主控实体
- MQ 连接 Master 与 Slave 所有服务通信的中间件
- Slave - 具体执行业务的实体
- 功能单元:具备一种执行任务的能力,但是只能执行一种,可以直接向 Master 汇报生存状况和结果,脱离节点也可以存在
- 节点:可以管理多个功能单元,但是不实现执行任务的接口,也并没有执行任务的能力,可以直接向 Master 汇报生存状况和结果(结果来源于功能单元)
好的,我们用下面这个图来简单说明一下结构

同时,这个整体的架构并不够我们描述整个框架,也显得非常敷衍,所以我们很有必要做详细的阐述:
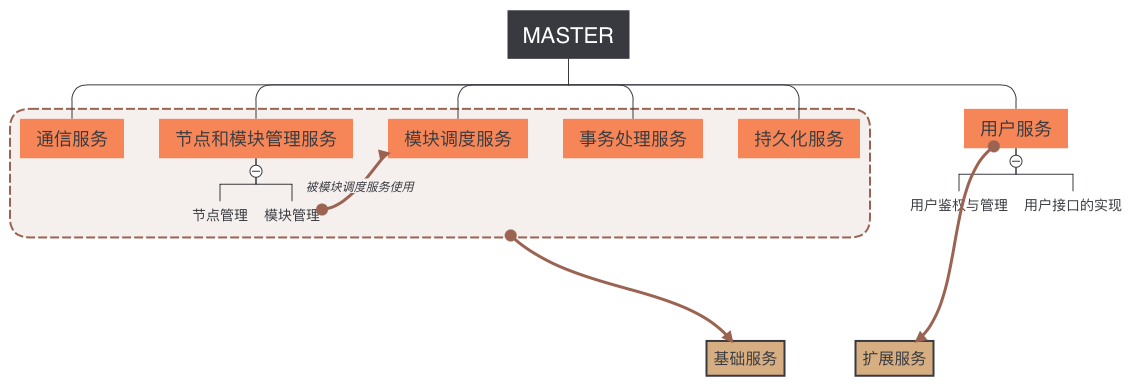
Master 拆分服务与子功能
Master 是一个巨大的功能集合,但是并不是一个“牛类”这样的东西,Master 是由很多个服务构成的,因此我们非常有必要把 Master 拆分成具体的服务来分别阐述其用途。
- 通信服务
- 节点和模块管理服务:提供对 Slave 的管理功能
- 节点管理子服务
- 模块(功能单元)管理子服务
- 模块调度服务:调度模块/功能单元之间的协作逻辑
- 事务处理服务
- 任务处理子服务
- 结果处理子服务
- 持久化服务:存储任务和结果
- 用户服务
- 用户鉴权与管理(后期)
- 用户接口

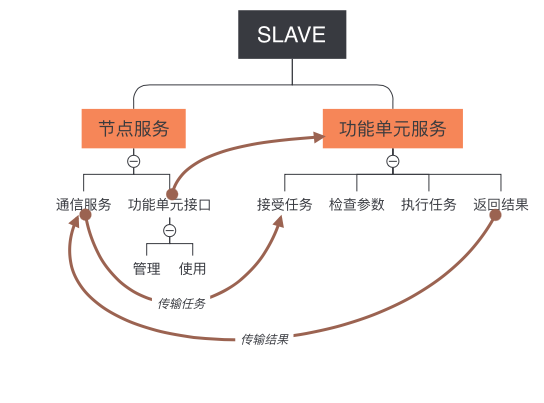
Slave 拆分服务与子功能
- 节点服务
- Master 通信服务
- 控制信道:传递主控节点的控制信息
- 任务信道:任务接收信道
- 结果信道:结果汇报
- 汇报信道:额外信息汇报
- …...
- 功能单元管理子服务
- 功能单元使用子服务
- 功能单元服务
- 接收任务
- 检查参数与合理性
- 执行任务
- 返回最终结果或者阶段性结果

其他设备
- 消息队列(集群):在下一个 Topic 会着重探讨。
过程设计
设计对应需求,我们仍然需要对重要的过程进行设计,和上面服务/功能拆分是不同的角度,但是也很好的可以描述出框架工作的过程。所以我个人觉的这个角度来做一些说明是非常有必要的。
事务处理流程
事务处理不论是在各种门户的微服务架构中还是在电商微服务架构都起着非常重要的作用:
事务的存在是为了保障任务执行的完整性和精确性,举个例子说明事务的存在的必要:当你的事情开始执行了,但是由于节点崩溃或者网络原因,没有办法成功执行这个操作,在收到执行失败的信号之后,事务会回滚到上一个安全的状态,这样就避免了 Pending 这种薛定谔状态,也是最终一致性的一种体现或者实现方法吧(当然事务控制中心我们这里只设置一个,就不存在多个事物控制中心数据的需要强同步的问题了)
我们在设计这个框架的时候有意将事务这个概念引入我们的框架,运用最终一致性处理事务处理
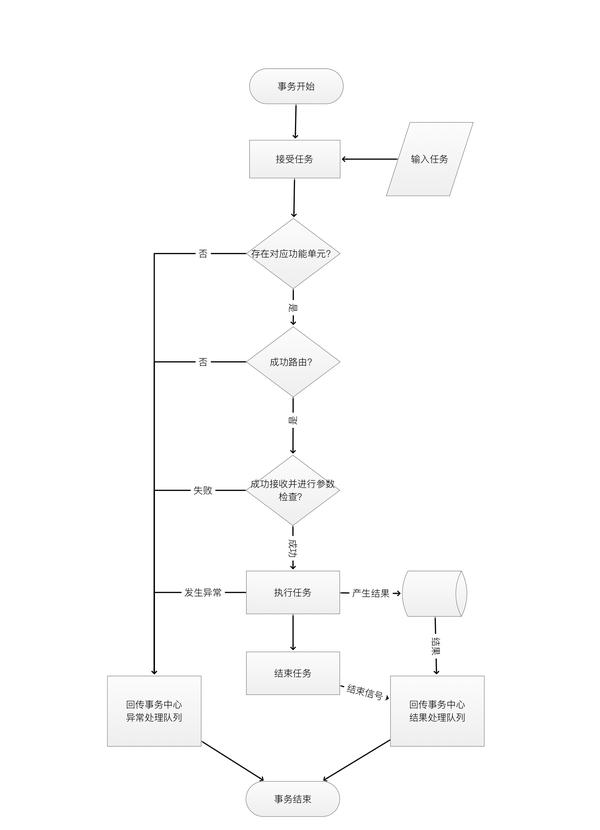

功能单元生存周期
当然理应所有的功能实体都应该有一个状态机,但是由于篇幅所限,我们就举个简单的例子,功能单元的生存周期状态图如下
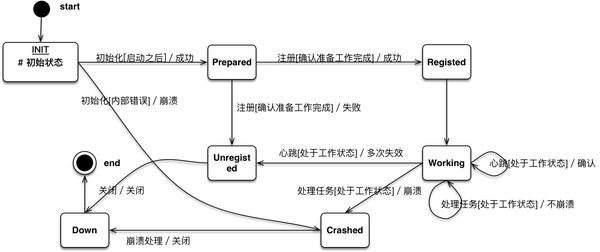

在功能单元启动之后,首先进入初始状态,进行初始化,初始化成功则进入 Prepared 状态,如果初始化失败,造成功能单元崩溃,则进入崩溃处理流程。
在 Prepared 状态下,功能单元自动发起注册到 Master,如果注册成功,改变状态为 Registered,如果失败,进入 Unregistered 状态。
Registered 状态直接进入 Working 状态,Working 状态下,会定时发送心跳(或者其他机制来保证与 Master)连接,如果发生多次连接断开,则进入 Unregistered 状态。同时在 Working 状态下进行事务处理(略)。如果事务处理过程中程序遭遇到不可解决的崩溃,则进入 Crashed 状态。
Crashed 状态下,我们需要重置功能单元决定是停止功能单元,还是重启。
Unregistered 状态会自动关闭功能单元,因为 Unregistered 是一个标志着功能单元正常结束的单元。
在上一个话题中,我们关于消息队列(通信)的部分并没有做太多的描述,接下来我们就在下一个话题中具体阐述一下关于节点通信的问题。
Topic - 通信与消息队列
本部分与大家简单探讨本框架的架构与消息队列的关系和对消息队列的设计。
消息队列基础
参考资料:https://tech.meituan.com/mq-design.html
RabbitMQ: https://www.rabbitmq.com/reliability.html
必要性
对于我们的渗透测试系统,消息队列真的是必须的么?我个人的回答是必须的。
主要特性:解决服务(模块)通信问题
通信不仅仅是 “我发送,你收到” 这么简单的事情。从本文框架的架构整体上来说,是一个 Master / Slaves 的架构模式,也就是说一个 Master 和多个 Slaves 同时进行通信,当然通信的种类也多种多样:
- 任务分发通信(多对多):Master 向 Slaves 分发任务,这个通信模型更像是一个 Producer / Consumer 的模式,这很好理解,Master 发送任务,Slaves 执行,我们自然保证并不想多个 Slave 同时来做一个任务,这样就白白浪费了资源。
- 通知与订阅消息通信(一对多):可以简单想象一下广播与组播的需求,这种通信模型我们可以暂且称之为 FanOut 吧。其实这也非常好理解,当你的 Master 想要发送一个通知消息,这个消息可能是针对全体的 Slaves 的,这样最合适的办法就是使用广播通信模式;同样的,当你的 Master 想要针对某一个组发送通知(例如关闭所有的爬虫模块组,升级某一个组的数据库,或者更新代码,部署新的功能),这类通知你是不希望被其他无关组或者无关节点收到的。针对这些情况,FanOut 可以很好解决。
- 点对点(一对一):这里主要不涉及 Slave 与 Slave 的通信,我们的架构似乎并不喜欢 Slave 与 Slave 之间有联系,这样会极大增加耦合度和复杂度;但是 Master 到 Slave 的单点通信时必须要有的,因为我们经常会需要单独告诉一个 Slave 应该干啥(关闭 Slave,重启 Slave 甚至 升级 Slave)
- 结果汇报与生存状况汇报(多对多):作为无状态的 Slave,完成一个任务的第一件事,应该就是把任务传回 Master;当然,作为 Master,是有必要知道 Slave 的一些生存状况的,除了主动问询的方法之外,Slave 还应该主动向 Master 进行汇报;同时,Slave 的关键部分挂掉了,错误信息/日志,也应该传回 Master…… 这样的需求其实一点都不过分,我们需要一个 FanIn 的模型去解决这种问题。
次要特性:可靠性/安全性
- 可靠性:在正常工作的条件下,你的通信两端拿到的数据是无差别的不会出现数据的差别,并且不会无故丢失数据,出现不期望的数据。你可以信赖你的数据来源。
- 安全性:不希望数据被别人截取造成信息泄漏,或者因为反序列化漏洞造成 RCE,或者命令注入,或者未知的风险,通信需要支持 SSL
而一个可靠的消息队列,它本身会有一整套的机制保证消息从一端到另外一端是可靠的,你可以不必担心你的消息在通信的过程中丢失/在消息队列中丢失(因为机器重启或其他不可预料的因素)。我们以 RabbitMQ 做例子,举例一下 RabbitMQ 在数据可靠性和一致性上做的一些工作:
Ensuring Messages are Routed
In some circumstances it can be important for producers to ensure that their messages are being routed to queues (although not always - in the case of a pub-sub system producers will just publish and if no consumers are interested it is correct for messages to be dropped).
确保消息一定是被路由处理的:在绝大多数情况下,RabbitMQ 都可以让生产者确认消息通过路由已经被传递进了消息队列中(除了没有订阅者的 发布-订阅 系统)
At the Consumer
In the event of network failure (or a node crashing), messages can be duplicated, and consumers must be prepared to handle them. If possible, the simplest way to handle this is to ensure that your consumers handle messages in an idempotent way rather than explicitly deal with deduplication.
在节点崩溃或者网络错误的时候,消息可能会出现重复,与此同时消费者必须对重复有解决办法。如果想解决这个问题,最简单的方法就是使用幂等这种方法(而不是直接处理)。
If a message is delivered to a consumer and then requeued (because it was not acknowledged before the consumer connection dropped, for example) then RabbitMQ will set the redeliveredflag on it when it is delivered again (whether to the same consumer or a different one).
...
Conversely if the redelivered flag is not set then it is guaranteed that the message has not been seen before. Therefore if a consumer finds it more expensive to deduplicate messages or process them in an idempotent manner, it can do this only for messages with the redeliveredflag set.
如果一个已经被送到了接收方,但是因为没有 ACK,消息会被重新进入消息队列;但是如果你想让消息再回到这个没有 ACK 的接受方,你需要向让你的消息设置一个 Redeliveredflag,如果这样的话,你的接收方会重新接受到那个没有 ACK 的信息。
…
反过来说如果 redelivered flag 没有被设置的话,就可以确保你接收方都不会受到重复的消息了。因此吧,我们其实并不是必须在应用业务层进行幂等方法,可以简单的使用消息队列的这个特性。
选型(可编程的协议 - RabbitMQ)
我们在这里选择 RabbitMQ 作为我们消息队列支持,接下来结合 RabbitMQ 的特征和我们的框架特性,我们可以尝试简单设计一下关键的消息队列结构。其实对于我们的 RabbitMQ 来说,消息队列的设计也会相当愉快,我们的发送方其实是不知道接收方具体的消息队列的,消息队列其实只是一个存在于接收方的概念。在发送方,只有交换机和路由的概念。所以我们可以使用不同交换机的种类配合路由来实现。
交换机
在 RabbitMQ 中,交换机有四种类型:
- Direct Exchange(直连交换机):由 routing_key 提供一对一的直连服务,这样就可以解决 Master 到单个节点或者功能单元的问题。
- Fanout Exchange(扇出交换机) :提供一(一个交换机)对多的消息交换服务,可以解决 Master 到所有节点的通知问题,但是这个需求实际上并不是特别的必要(除了整个系统在进行大的升级/关闭的时候),并不是非常常用。
- Topic Exchange(主题交换机) :这个其实也可以说是和 Fanout Exchange 有一点类似,只要订阅了一个主题就可以收到这个主题的相关信息了,当然订阅主题的方法也十分灵活。我们可以通过这个交换机,向各个组/ 类型/具有某个预设特征的功能单元或者节点发送消息。
- Header Exchange(首部交换机) : Direct Exchange 的另外一种表现形式,只是不是使用 routing_key 进行路由的,是由本身的一个 headers 来控制的。
根据这四种类型的交换机,我们很容易设计出我们的通信系统。(当实际的使用,我们并不会全部选择)
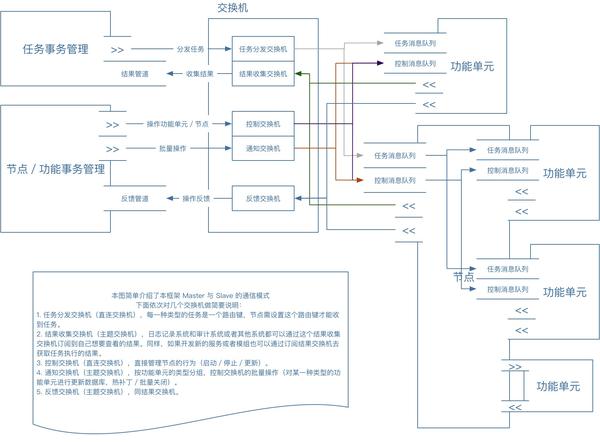

下面依次对几个交换机做简要说明:
- 任务分发交换机( Direct Exchange ),每一种类型的任务是一个路由键,节点需设置这个路由键才能收到任务。在客户端,每一类型的功能单元要设置相同的路由键(类型名),才可以接收到任务
- 结果收集交换机( Topic Exchange ),日志记录系统和审计系统或者其他系统都可以通过这个结果收集交换机订阅到自己想要查看的结果。同样,如果开发新的服务或者模组也可以通过订阅结果交换机去获取任务执行的结果。
- 控制交换机( Direct Exchange ),直接管理节点的行为(启动/停止/更新),当然这个控制交换机的路由键为这个节点的 GUID 或 UUID,这样可以实现 Master 到 Slave 的单点链接。
- 通知交换机( Topic Exchange ),按功能单元的类型分组,控制交换机的批量操作(对某一种类型的功能单元进行更新数据库,热补丁/批量关闭)。
- 反馈交换机( Topic Exchange ),同结果交换机。
其中,任务分发和结果收集是属于事务(任务)管理服务的,控制/通知/反馈交换机是属于节点(功能单元)管理服务的。这样我们可以把管理与业务,通过消息队列进行完美分离。
上文描述了一个分布式渗透框架该有的部分,但是限于篇幅,我们没有办法把每一个部分都的设计思路都描述清楚。笔者能力有限,文中如有纰漏,希望读者不吝赐教。
PS: 知乎的编辑器莫名其妙粒子态吃掉列表的 Tab 导致列表出现格式 Bug,笔者经过尝试无法修好 ?
